Savremena biznis dilema – Skladišta podataka ili Jezera podataka

Možemo slobodno reći da se poslovanje u digitalno doba ne može zamisliti bez korišćenja neke forme baze podataka. Pod formom pre svega mislimo na formu skladištenja tih podataka, čime ćemo se zapravo i baviti u ovom tekstu.
U današnjem poslovnom svetu biti u korak sa poslovnim trendovima za jednu kompaniju znači da ona pre svega treba da bude u stanju da prikupi, skladišti, a na kraju i obradi ogromnu količinu podataka. Bilo da su u pitanju eksterni ili interni podaci, podaci prikupljeni iz odeljenja prodaje, marketinga ili iz nekog vašeg online izvora, bitno je da te podatke pravilno prikupite, analizirate i iz njih izvučete što više korisnih informacija za vaš biznis.
Ukoliko ste se do sada sretali sa pojmom Big Data, onda već znate o kakvoj vrsti podataka govorimo. Ako kojim slučajem niste, onda je važno da znate da Big Data zapravo podrazumeva ogromne količine kompleksnih podataka koji se ne mogu obrađivati tradicionalnim aplikacijama za obradu podataka. Pre svega to nije moguće zbog njihove raznovrsnosti i količine.
Ti podaci mogu biti iz različitih poslovnih izvora, aplikacija, uređaja, i po pravilu oni nisu mnogo kompatibilni jedni sa drugima. U zavisnosti od toga koji su sve izvori podataka u pitanju i u kojoj količini su prisutni u bazama, zavisi i za koju arhitekturu podataka će se kompanija opredeliti.
Dve najpopularnije opcije kada je u pitanju Big Data tehnologija su Skladište podataka (Data Warehouse) i Jezero podataka (Data Lake).
Skladišta podataka
Na prvom nivou Big Data repozitorijuma nalaze se Skladišta podataka. Skladišta podataka se preko API servisa ili sirovih datoteka pune iz različitih izvora podataka, odnosno poslovnih jedinica unutar jedne kompanije (npr. odeljenje prodaje, odeljenje marketinga, korisnički servis itd). Na taj način podaci unutar Skladišta podataka bivaju formirani u obliku skupova podataka koji sadrže podatke grupisane pod određenom kategorijom.
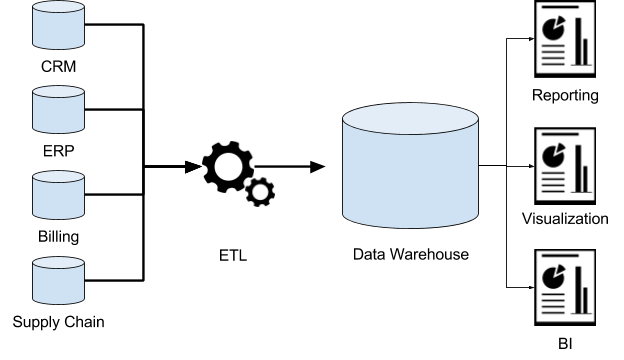
U zavisnosti od konkretnih potreba neke kompanije razlikovaće se i način na koji će ti podaci biti eksportovani iz njihovog izvora i importovani u Skladište. Dva su osnovna modela koja se danas najčešće primenjuju u praksi:
ETL model i ELT model
Postoje dva uobičajena modela prilikom eksportovanja i importovanja podataka iz izvornih sistema u Skladište podataka. To su ETL model i ELT model (veoma sličnih naziva ali prilično različitog dizajna).
Primarna razlika između ova dva modela je tačka u pipeline-u za obradu podataka na kojem se događaju transformacije prilikom importovanja podataka. Upravo od toga toga zavisi na koji način će ovi podaci biti importovani u Skladište.
Prvi obrazac je ETL (Extract-Transform-Load), koji transformiše podatke pre nego što se oni učitaju u Skladište.
Drugi obrazac je ELT (Extract-Load-Transform), koji učitava izvorne podatke u Skladište, a zatim koristi SQL i moć Massively Parallel Processing (MPP) arhitekture za izvođenje transformacija u samom Skladištu.
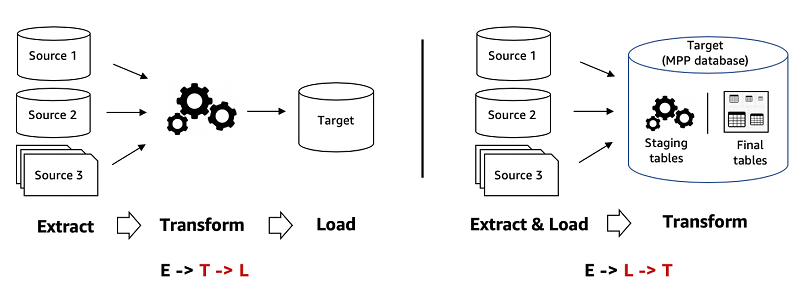
ETL model se najčešće koristi ukoliko postoji potreba za detaljnijim čišćenjem podataka pre njihovog importovanja i kada su potrebna brojna složena izračunavanja različitih podataka
ELT se najčešće primenjuje kada je potrebno obraditi velikih skupove podataka. Nerelacioni i nestrukturirani podaci više odgovaraju ELT modelu, jer se podaci iz izvora kopiraju upravo onakvi kakvi jesu, odnosno u njihovom izvornom obliku.
Bez namere da ulazimo u detaljno pojašnjenje koji bi od modela bio prihvatljiviji za neku kompaniju, navešćemo samo neke osnovne prednosti ELT modela:
Jedna od glavnih prednosti ELT modela u odnosu na ETL model je smanjenje vremena učitavanja. Drugim rečima, on je nešto brži, pa korišćenje ELT modela smanjuje vreme koje podaci provode u tranzitu i obično je isplativije. Pored toga, zahvaljujući računarskoj snazi savremenih sistema za skladištenje podataka, brzina i efikasnost ELT modela još više dolazi do izražaja u odnosu na tradicionalni ETL model.
Takođe, korisnost i upotrebna vrednost podataka importovanih primenom ELT modela je veća, jer su u pitanju sirovi podaci koji su učitani u njihovom izvornom stanju.
Dakle, za kompaniju koja želi da analizira velike, ali strukturirane skupove podataka, Skladište podataka je dobra opcija. U stvari, ako je kompanija zainteresovana samo za deskriptivnu analitiku, odnosno proces objedinjavanja podataka koji već postoje, Skladište podataka može biti sve što joj je potrebno.
Recimo, menadžment kompanije želi da analizira podatke o prodaji tokom određenog vremenskog perioda, broju online upita o proizvodu i podatke o pregledu promotivnih videa. U tom slučaju Skladište podataka je idealan izbor jer su svi ti podaci u njemu spremljeni u obliku strukturiranih podataka.
Jezera podataka
Već smo pomenuli da Skladišta podataka obično skladište i obrađuju određene skupove podataka. Takvo skladište podataka svakako ima svojih prednosti, ali sa druge strane skupovi podataka ponekad mogu da daju nedovoljno jasnu sliku koja se tiče celokupne poslovne aktivnosti preduzeća. Tu se kao izuzetno korisna javljaju Jezera podataka.
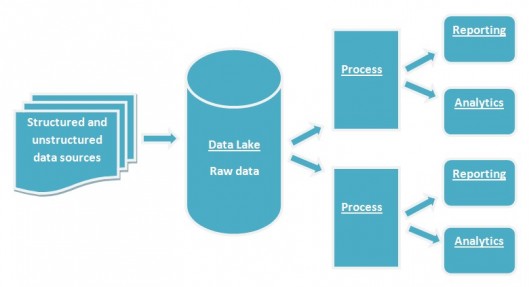
U svom osnovnom principu Jezera podataka su vrlo slična Skladištima podataka. Osnovna razlika je u tome što jezera putem API servisa uvlače i obrađuju podatke iz unutrašnjih i eksternih izvora u bilo kom formatu (strukturirani i nestrukturirani) i u njihovom izvornom obliku.
Tako, na primer, Jezera podataka omogućavaju velikoj kompaniji da ima jedno centralno mesto za skladištenje i obradu podataka iz unutrašnjih izvora, poput podataka o prodaji proizvoda ili usluga, i ujedno i obradu eksternih podataka kao što su npr. merenje performansi kanala digitalnog marketinga iz eksternih marketinških agencija.
Podaci u Jezeru podataka se ne transformišu sve dok ne budu potrebni za analizu, a zatim se primenjuje šema čitanja koja omogućava da se prikupljeni podaci mogu analizirati.
Jezera podataka omogućavaju korisnicima da im pristupe i istražuju na svoj način, bez potrebe da ih premeštaju u drugi sistem. Izveštaji dobijeni iz jezera podataka obično se izvršavaju u hodu, umesto da se redovno izvlače analitički izveštaji sa druge platforme ili recimo iz Skladišta podataka.
Naravno, po potrebi se za analizu podataka može primeniti i automatizacija procesa, koja će omogućiti kreiranje izveštaja iz dostupnih podataka.
Zaključak
Skladišta podataka već duže vreme predstavljaju standard za čuvanje i obradu podataka u mnogim organizacijama. Taj model sam po sebi nije bio idealan, jer nije eliminisao potrebe za grupama podataka (tzv. silosi) koje su postojale između unutrašnjih i eksternih izvora podataka. U traženju načina da se obezbedi što širi pristup izvornim podacima, sa što manje odstupanja od originala, kao rešenje se pojavio koncept Jezera podataka.
Kao što smo već pomenuli, Jezera podataka predstavljaju centralizovana skladišta koja su u stanju da uskladište podatke različite strukture iz bilo kojeg izvora i u bilo kom formatu.
Iako je sposobnost ispravnog arhiviranja i obrade podataka neophodna za bilo koji napredni proces zansovan na Poslovnoj inteligenciji i jedan i drugi model imaju neke svoje mane i prednosti:
- Skladišta podataka, zbog načina na koji uvlače podatke, mogu potencijalno imati netačne ili neadekvatne podatke, što može uticati na tačnost prilikom formiranja izveštaja.
- Jezera podataka mogu postati tzv. močvare podataka (kako ih ponekada u negativnom kontekstu nazivaju), jer zbog svoje ogromnost i složenost importovanih podataka mogu otežati rad sa njima. Ova činjenica zajedno sa činjenicom da su Jezera podataka ujedno i prilično skupa, dovoljna je da menadžment neke kompanije okleva da pređe na ovaj model, sve dok ne budu sigurni da njihovi podaci u tom modelu mogu biti pravilno analizirani i upotrebljeni.
- Jezera podataka zahtevaju da analitičari imaju iskustvo u svakom koraku (svakoj tački podataka) da bi pravilno obradili i aktivirali podatke, što posredno dovodi i do problema nedostupnosti dovoljnog broja raspoloživih stručnjaka za ovu tehnologiju.
- Trenutno ne postoji univerzalno prihvaćeni skup pravila, standarda ili smernica o upravljanju podacima u Jezerima podataka. S obzirom da je standardizacija preduslov masovnije primene neke tehnologije, ovo za sada može predstavljati neku vrstu prepreke za širu implementaciju ovog modela.
Imajući sve navedeno u vidu, čini se da iako prisutne tehnologije, ni Skladišta podataka ni Jezera podataka nisu još uvek našle svoju punu primenu u svetu Poslovne inteligencije.
Manje kompanije mogu videti veću prednost u Skladištima podataka jer se mogu lakše fokusirati na određene grupe njima bitnih podataka i tako obezbediti potrebne informacije za svoje poslovanje.
Sa druge strane, velike kompanije mogu više težiti ka Jezerima podataka jer zbog svoje kompleksne organizacije i mnoštva paralelnih poslovnih aktivnosti, mogućnost rada sa velikim grupama izvornih podataka može biti veoma korisno za njihov poslovni uspeh.
Činjenica je da, koliko god svet podataka dobija neke drugačije forme, proći će još neko vreme pre nego što kompanije u većoj meri počnu da ih primenjuju i osećaju pozitivan uticaj na njihovo poslovanje.


